Alle rechten voorbehouden aan de auteur.
Computers verwerken gegevens. De verwerking van gegevens (data) gebeurt aan de hand van welbepaalde regels (instructies) in een computerprogramma.
Zowel de instructies als de data bevinden zich in het geheugen van de computer. Het geheugen is een reeks genummerde cellen met een vaste capaciteit, bijvoorbeeld 32 bits. Het nummer van een cel heet het adres van die cel.
Op het laagste niveau is er geen strikt onderscheid tussen data en instructies. Er bestaan zelfs computerprogramma's die zichzelf wijzigen.
De meeste computers beschikken over een speciale cel, de programmateller (program counter), die het (veranderlijke) adres bevat van één gewone geheugencel. De normale werking van de computer verloopt dan door eindeloos het volgende schemaatje te herhalen:
De volgende keer dat we het schema doorlopen, wordt natuurlijk niet meer dezelfde instructie gelezen, omdat inmiddels de programmateller een hogere waarde heeft gekregen. Zo kunnen verscheiden instructies na elkaar in het geheugen van de computer een heel programma vormen. Het vierpunten-schema heet ook de Von Neumanncyclus, naar de wetenschapper John Von Neumann die het heeft bedacht.
Bovenstaand schema is om twee redenen onvolledig:
Soms kan het wenselijk zijn, de normale volgorde van de instructies te wijzigen: bijvoorbeeld omdat een stukje van het programma moet worden overgeslagen, of omdat een zopas afgelopen stukje moet worden herhaald. Daartoe bestaan er sprongopdrachten. Een sprongopdracht is een instructie zoals een andere, die echter een wijziging uitvoert in de inhoud van de programmateller. Het gevolg van een sprongopdracht is dat bij de volgende cyclus niet de instructie wordt gelezen die onmiddellijk op de spronginstructie volgt, maar een instructie ergens anders in het geheugen.
We onderscheiden voorwaardelijke en onvoorwaardelijke sprongopdrachten. Bij het voorwaardelijke sprongopdracht wordt de inhoud van de programmateller soms gewijzigd, en soms niet, al naargelang het resultaat van een eenvoudige test (bijvoorbeeld, of de inhoud van een bepaalde geheugencel de waarde 0 heeft). Bij een onvoorwaardelijke sprongopdracht wordt de inhoud van de programmateller in elk geval gewijzigd.
Programmeren in processor-instructies, ook wel machinecode genoemd, is moeilijk en tijdrovend. Zelfs het gebruik van een assembleerprogramma (waardoor de instructies als tekst kunnen worden ingevoerd, in plaats van als hexadecimale of binaire getallen) is beperkt tot programma's van hooguit enkele duizenden instructies.
Een hogere programmeertaal is een reeks afspraken om vaak voorkomende constructies in computerprogramma's samen te vatten in eenvoudige stukken tekst. Een hogere programmeertaal kan dus niet méér dan assembler of machinecode: ze is alleen beter aangepast aan het menselijk denkproces, in dit geval het creatieve werk van de programmeur.
Er is geen eensgezindheid op de markt van de hogere programmeertalen. Sommigen verdedigen fervent de moderne versies van de pionier-talen: Basic, Cobol, Fortran, PL/I, RPG. Anderen zweren bij de iets recentere Pascal (thans Oberon), Modula of C. Een groot aantal programmeurs zoekt thans heil in de zogenaamde object-georiënteerde programmeertalen als Java, C++, Smalltalk en Eiffel.
De meeste hogere programmeertalen maken een onderscheid tussen data en instructies. Typisch wordt aan het begin van het programma een opsomming gegeven van alle datastructuren die de programmeur wenst te gebruiken: de declaratie van veranderlijken. Vervolgens bevat het programma de instructies die de datastructuren lezen, bewerken en opvullen: de opdrachten.
Object-georiënteerd programmeren onderscheidt zich juist doordat de scheiding tussen data en instructies iets minder strikt wordt volgehouden. Maar er is nog steeds een verschil tussen de data die de toestand van een object beschrijven (eigenschappen) en de instructies die het gedrag van het object definiëren (methoden). We verwijzen hiervoor naar de desbetreffende cursus in de tweede licentie.
Cobol is een regel-georiënteerde taal. Een Cobol-programma bestaat uit een aantal afzonderlijke regels, waarvan de lengte telkens maximaal 80 tekens bedraagt.
In de praktijk zijn slechts de tekenposities 8 tot en met 72 beschikbaar voor programmacode, zodat een regel in feite niet langer dan 65 tekens mag zijn.
Verticaal bestaat een Cobol-programma uit vier grote delen, divisions genaamd:
Elke division, behalve de eerste, bestaat uit 1 of meer sections.
De identification division bevat informatie over het programma als geheel: naam, auteur, datum, enz.
De environment division beschrijft de context waarin het computerprogramma draait. Ze bestaat uit enerzijds de configuration section, met een beschrijving van de diverse betrokken machines, en de input-output section, waarin bestanden en andere media voor invoer en uitvoer aan bod komen.
De data division definieert de gegevensstructuren die het programma hanteert: enerzijds de gegevensstructuren voor invoer en uitvoer, in de file section, anderzijds de gegevensstructuren voor intern gebruik, in de working-storage section.
De procedure division bevat de eigenlijke programma-instructies voor de verwerking van de gegevens. Een eventuele opdeling in sections wordt hier door de programmeur zelf bepaald.
Hier is een voorbeeld van een compleet, werkend Cobol-programma. De bovenste twee regels maken geen deel uit van het programma zelf, en geven alleen de positienummering van de tekens op een regel aan.
11111111112222222222333333333344444444445555555555666666666677777777778
12345678901234567890123456789012345678901234567890123456789012345678901234567890
IDENTIFICATION DIVISION.
PROGRAM-ID. Hier.
AUTHOR. Lieven Smits.
ENVIRONMENT DIVISION.
DATA DIVISION.
PROCEDURE DIVISION.
Toon-boodschap.
DISPLAY "Hier ben ik!"
STOP RUN.
We reiken nu enkele elementaire bouwstenen aan voor het schrijven van eenvoudige Cobolprogramma's:
Declaraties maken deel uit van de DATA DIVISION.
De andere drie opdrachten horen thuis in de
PROCEDURE DIVISION.
In plaats van elk van de vier bouwstenen met een apart voorbeeld te illustreren, geven we op het einde een compleet werkend Cobol-programma waarin ze alle vier aan bod komen.
Elke veranderlijke heeft een naam. De naam moet bestaan uit letters, cijfers en enkele speciale leestekens (eigenlijk alleen het verbindingsstreepje - en het streepje onderaan de regel _). De naam moet met een letter beginnen.
Veranderlijken die eigen zijn aan ons programma, zonder dat
ze ergens in een bestand op de harde schijf terechtkomen,
heten niet-persistente veranderlijken. Niet-persistente
veranderlijken declareren we in de
WORKING-STORAGE SECTION van de DATA DIVISION,
en wel als volgt:
77 naam PIC formaat .
Het getal 77 en het sleutelwoord PIC (of voluit
PICTURE) typen we voorlopig gewoon over, zonder er een
speciale betekenis aan te hechten. Het formaat
van de veranderlijke bepaalt de vorm en de grootte van de veranderlijke.
In het geval van een numerieke veranderlijke betekent dat bijvoorbeeld:
het aantal cijfers vóór en na de decimale punt.
Het formaat van een veranderlijke waarop nog rekenkundige bewerkingen
moeten kunnen uitgevoerd worden, luidt bijvoorbeeld
9999V99, dat betekent: vier decimale cijfers
vóór, en twee na de komma.
Je kan gegevens die de gebruiker invoert via het toetsenbord,
opslaan in een veranderlijke door de ACCEPT-opdracht.
De algemene vorm luidt
ACCEPT naam .
Het is de verantwoordelijkheid van de gebruiker dat de ingevoerde gegevens overeenkomen met het gespecifieerde formaat van de veranderlijke. Het is de verantwoordelijkheid van de programmeur, zich te wapenen tegen fouten van de gebruiker.
Je programma produceert een regel uitvoer wanneer het
de DISPLAY-opdracht tegenkomt. De algemene
vorm van deze opdracht is
DISPLAY output .
en daarin kan output zowel de
naam van een veranderlijke zijn (waarvan de inhoud
op het scherm moet worden getoond), als een
constant getal of een tekst tussen dubbele aanhalingstekens.
Met behulp van de COMPUTE-opdracht plaatsen we het
resultaat van een rekenkundige bewerking in een veranderlijke.
De algemene vorm luidt
COMPUTE naam = uitdrukking .
De uitdrukking is samengesteld met
behulp van andere veranderlijken, letterlijke constanten,
de bewerkingstekens
+ optelling- aftrekking* vermenigvuldiging/ deling** machtsverheffing
en haakjes (). De haakjes dienen om de
volgorde der bewerkingen te beïnvloeden. Zonder
haakjes geldt de normale volgorde uit de algebra:
eerst machtsverheffing, dan vermenigvuldiging en deling
(onderling van links naar rechts), tenslotte optelling
en aftrekking (onderling van links naar rechts).
Het volgende Cobol-programma berekent de intrest op een geleend kapitaal voor een gegeven rentevoet. Zowel de grootte van het kapitaal als de rentevoet (in percent) moeten door de gebruiker via het toetsenbord worden ingebracht.
IDENTIFICATION DIVISION.
PROGRAM-ID. Intrest.
DATA DIVISION.
WORKING-STORAGE SECTION.
77 KAPITAAL PIC 9(10).
77 RENTEVOET PIC 9(2)V9(2).
77 INTREST PIC Z(9)9.9(2).
PROCEDURE DIVISION.
BEREKEN-INTREST.
DISPLAY "Geleend kapitaal ? ".
ACCEPT KAPITAAL.
DISPLAY "Rentevoet in percent: ".
ACCEPT RENTEVOET.
COMPUTE INTREST = KAPITAAL * RENTEVOET / 100.
DISPLAY "Periodieke intrest: ".
DISPLAY INTREST.
STOP RUN.
In de WORKING-STORAGE SECTION worden drie
numerieke veranderlijken gedeclareerd: KAPITAAL,
RENTEVOET en INTREST. De eerste
is een geheel getal van ten hoogste tien cijfers; de tweede
een getal van ten hoogste twee cijfers vóór en
twee cijfers na de komma (we gaan ervan uit dat geen
woekerrente van meer dan 100 percent gevraagd wordt
- hoewel dat natuurlijk theoretisch niet uitgesloten is).
De derde veranderlijke krijgt een lichtjes verschillend
formaat, omdat ze op het scherm moet getoond worden.
De declaratie
77 INTREST PIC Z(9)9.9(2).
betekent: tien cijfers vóór de komma, waarvan de eerste negen niet moeten getoond worden als het onbeduidende nullen zijn; daarna een decimale punt, en daarna precies twee cijfers (ook als het nullen zijn).
De PROCEDURE DIVISION begint met
twee keer achtereenvolgens een DISPLAY
(met constante tekst) en een ACCEPT.
De gebruiker wordt namelijk telkens netjes
op de hoogte gebracht welk gegeven
hij moet invoeren.
Nadat ons programma zijn twee invoergegevens heeft verworven, komt de eigenlijke berekening. In de volgende Cobol-code herkennen we gemakkelijk de gewone intrestformule.
COMPUTE INTREST = KAPITAAL * RENTEVOET / 100.
Wat zou er verkeerd gaan als we in plaats daarvan het volgende zouden schrijven ?
COMPUTE INTREST = KAPITAAL * RENTEVOET / 100.
De laatste twee regels tonen het resultaat van de berekening op het scherm, eerst een constante tekst en dan het eigenlijke rekenresultaat.
DISPLAY "Periodieke intrest: ".
DISPLAY INTREST.
Typ bovenstaand programma in, bewaar het
met de naam Intrest,
compileer het en voer het uit met als
kapitaal 15000 en als rentevoet 3.4 percent.
Experimenteer ook veelvuldig met gegevens die
niet aan het juiste formaat voldoen, bijvoorbeeld
een kapitaal van 100 miljard, of een rentevoet
van 3.4567 percent. Ga na hoe je programma
hierop reageert.
Programmeren volgens het stap-sprongmodel mag dan theoretisch onbegrensde mogelijkheden bieden, in de praktijk worden dergelijke programma's moeilijk produceerbaar of onderhoudbaar vanaf een tienduizendtal opdrachten. De voornaamste oorzaak is dat de programmeur het overzicht verliest over de volgorde van de opdrachten, zoals die wordt gedicteerd door voorwaardelijke en onvoorwaardelijke sprongopdrachten. We spreken van spaghetti als een programma onoverzichtelijk wordt door de elkaar kruisende sprongopdrachten.
Onder invloed van ondermeer Edsger Dijkstra en C. Hoare werd vanaf de jaren 1960 gewerkt aan programmeertalen waarin het gebruik van sprongopdrachten aan strikte regels is gebonden. Ook in klassieke hogere programmeertalen kan de programmeur zichzelf een discipline opleggen waarbij sprongopdrachten aan dezelfde basisregels voldoen, om het programma overzichtelijk te houden. Deze programmeerdiscipline, of ze nu opgelegd wordt door de regels van de programmeertaal, dan wel door de vrijwillige inzet van de programmeur, heet gestructureerd programmeren. Programmeertalen die gestructureerd programmeren afdwingen of tenminste sterk aanmoedigen, zijn Algol, Pascal en C. Maar ook van de klassieke hogere talen zoals Cobol en Fortran ontstonden gestructureerde versies.
De regels van gestructureerd programmeren zijn tamelijk eenvoudig. Het komt erop aan dat alle afwijkingen van de normale, lineaire tijdsvolgorde der opdrachten slechts op de volgende drie manieren gebeuren:
Soms wordt de definitie ook negatief geformuleerd: een gestructureerd programma is een programma dat geen gebruik maakt van GO TO.
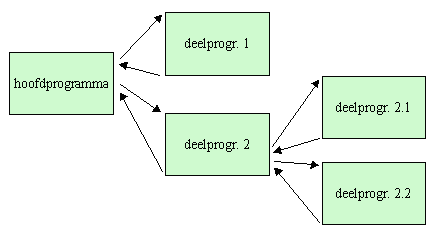
Een deelprogramma is een reeks instructies, soms ook met bijbehorende eigen gegevensstructuren, die een afgebakend functioneel onderdeel uitvoeren binnen de verzameling taken van een programma. Vaak gehoorde synoniemen zijn: subroutine, procedure, functie.
Deelprogramma's zijn ons voornaamste wapen bij het reduceren van complexe taken tot elementaire bouwstenen.
Het volgende diagram geeft schematisch weer hoe een programma een deelprogramma kan aanroepen, dat dan weer op zijn beurt een deelprogramma oproept, enzovoort. Het is geen stroomschema: stroomschema's zijn niet geschikt om het oproepen van deelprogramma's weer te geven.
In Cobol wordt een deelprogramma gemarkeerd door er een paragraaf naar te noemen. Het deelprogramma kan dan vanuit een ander programmagedeelte worden opgeroepen met de opdracht
PERFORM deelprogramma .
Als er een deelprogramma met de naam VERMENIGVULDIG-MATRIX bestaat,
dan roepen we het op met de opdracht
PERFORM VERMENIGVULDIG-MATRIX .
Laten we ons voorbeeldprogramma om intresten te berekenen, hernemen, maar we splitsen het werk op in drie afzonderlijke eenheden:
IDENTIFICATION DIVISION.
PROGRAM-ID. Intrest-met-deelprogrammas.
DATA DIVISION.
WORKING-STORAGE SECTION.
77 KAPITAAL PIC 9(10).
77 RENTEVOET PIC 9(2)V9(2).
77 INTREST PIC Z(9)9.9(2).
PROCEDURE DIVISION.
BEREKEN-INTREST.
PERFORM LEES-GEGEVENS.
PERFORM BEREKENING.
PERFORM TOON-RESULTAAT.
STOP RUN.
LEES-GEGEVENS.
DISPLAY "Geleend kapitaal ? ".
ACCEPT KAPITAAL.
DISPLAY "Rentevoet in percent: ".
ACCEPT RENTEVOET.
BEREKENING.
COMPUTE INTREST = KAPITAAL * RENTEVOET / 100.
TOON-RESULTAAT.
DISPLAY "Periodieke intrest: ".
DISPLAY INTREST.
Een paragraaf wordt voorafgegaan door zijn naam, te beginnen in kolom 7 en te eindigen met een punt en een regeleinde.
De opsplitsing in deelprogramma's voegt functioneel niets toe: het programma gedraagt zich nog net eender als tevoren. Ook de efficiëntie is er niet op vooruitgegaan, integendeel misschien. Toch verdient bovenstaande werkwijze zeker de voorkeur, omdat ze beter de onderliggende structuur van de toegepaste oplossingsmethode illustreert. Doordat het programma als het ware 'zichzelf verklaart', is het beter onderhoudbaar.
Onderhoudbaarheid is een belangrijke kwaliteitscomponent van computerprogramma's. Meer dan de helft van alle programmeerwerk betreft onderhoud van software, dat wil zeggen wijzigingen aan bestaande programma's.
De voorwaardelijke opdracht laat toe een opdracht al dan niet uit te voeren, naargelang een bepaalde voorwaarde voldaan is of niet.
Het stroomschema van de voorwaardelijke opdracht ziet er als volgt uit:
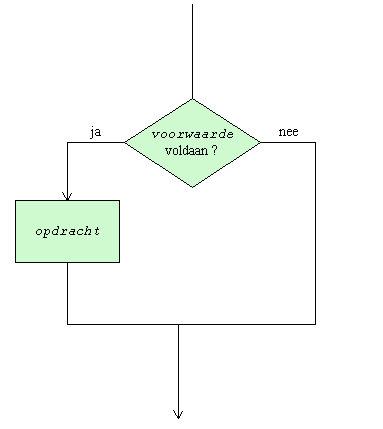
In Cobol wordt de voorwaardelijke opdracht ingeleid door het sleutelwoord IF. Haar algemene vorm luidt
IF voorwaarde opdracht .
De volgende opdracht halveert de inhoud van de
veranderlijke A, op voorwaarde dat die
inhoud aanvankelijk minstens 10 bedraagt.
IF A IS NOT LESS THAN 10 DIVIDE A BY 2 GIVING A.
Er bestaat ook een variant van de voorwaardelijke opdracht waarbij de programmeur een alternatieve opdracht voorziet voor het geval waarin de voorwaarde níet voldaan is. Het stroomschema van deze alternatieve vorm is
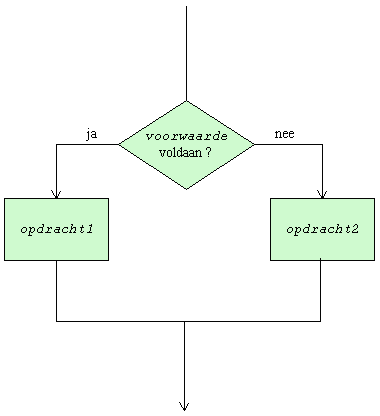
In Cobol wordt de alternatieve opdracht ingeleid door het sleutelwoord ELSE. De algemene vorm luidt
IF voorwaarde opdracht1 ELSE opdracht2 .
De volgende opdracht halveert of verdubbelt de inhoud
van de veranderlijke A, naargelang die inhoud
aanvankelijk minstens 10 of minder dan 10 bedraagt.
IF A IS NOT LESS THAN 10 DIVIDE A BY 2 GIVING A ELSE MULTIPLY A BY 2 GIVING A.
Een bijzonder geval van de tweede vorm van de voorwaardelijke
opdracht doet zich voor wanneer opdracht1
leeg blijft: er moet alléén iets gebeuren als
de voorwaarde niet voldaan is. In dat geval mag je
in plaats van opdracht1 de sleutelwoordgroep
NEXT SENTENCE schrijven.
De volgende opdracht gaan na of de veranderlijke LETTER
de letter "X" bevat. Als dat niet het geval is, dan wordt de inhoud
van LETTER vervangen door de letter "Z".
IF LETTER = "X" NEXT SENTENCE ELSE MOVE "Z" TO LETTER.
Het gebruik van NEXT SENTENCE kan natuurlijk altijd
vermeden worden: vervang gewoon de voorwaarde
door haar logische omkering. Zo is de vorige opdracht
gelijkwaardig met
IF LETTER NOT = "X" MOVE "Z" TO LETTER.
De lusopdracht laat toe een opdracht of een reeks opdrachten een aantal keer te herhalen. Hoe vaak, hangt af van de bijzondere soort lusopdracht:
Het volgende stroomschema illustreert de tweede vorm:
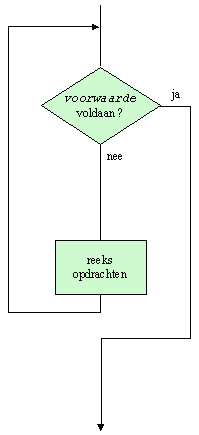
In Cobol moeten de te herhalen opdrachten gegroepeerd worden
in een deelprogramma. De lusopdracht is een variant van de
PERFORM-opdracht, waarmee deelprogramma's worden
opgeroepen:
PERFORM deelprogramma getal TIMES . PERFORM deelprogramma UNTIL voorwaarde .
Het volgende programma drukt een tabel af met de kwadraten van de eerste twintig positieve gehele getallen.
IDENTIFICATION DIVISION.
PROGRAM-ID. Kwadratentabel.
ENVIRONMENT DIVISION.
DATA DIVISION.
WORKING-STORAGE SECTION.
77 GRONDTAL PICTURE 99.
77 KWADRAAT PICTURE 999.
01 UITVOERLIJN.
02 GETAL PICTURE ZZZ9 OCCURS 2 TIMES.
PROCEDURE DIVISION.
DRUK-TABEL.
MOVE 1 TO GRONDTAL.
PERFORM VOER-LIJN-UIT UNTIL GRONDTAL IS GREATER THAN 20.
STOP RUN.
VOER-LIJN-UIT.
MULTIPLY GRONDTAL BY GRONDTAL GIVING KWADRAAT.
MOVE GRONDTAL TO GETAL(1).
MOVE KWADRAAT TO GETAL(2).
DISPLAY UITVOERLIJN.
ADD 1 TO GRONDTAL.
De UNTIL-versie van de PERFORM-lusopdracht kan nog worden uitgebreid met een stuurveranderlijke: een teller die de herhalingen nummert. De langere vorm van deze lusopdracht is
PERFORM deelprogramma VARYING veranderlijke FROM beginwaarde BY stapgrootte UNTIL voorwaarde .
Het vorige programma kan nu korter geschreven worden als
IDENTIFICATION DIVISION.
PROGRAM-ID. Kwadratentabel2.
ENVIRONMENT DIVISION.
DATA DIVISION.
WORKING-STORAGE SECTION.
77 GRONDTAL PICTURE 99.
77 KWADRAAT PICTURE 999.
01 UITVOERLIJN.
02 GETAL PICTURE ZZZ9 OCCURS 2 TIMES.
PROCEDURE DIVISION.
DRUK-TABEL.
PERFORM VOER-LIJN-UIT
VARYING GRONDTAL FROM 1 BY 1
UNTIL GRONDTAL IS GREATER THAN 20.
STOP RUN.
VOER-LIJN-UIT.
MULTIPLY GRONDTAL BY GRONDTAL GIVING KWADRAAT.
MOVE GRONDTAL TO GETAL(1).
MOVE KWADRAAT TO GETAL(2).
DISPLAY UITVOERLIJN.
Om complexe organismen te ordenen, gaan we er vaak allerlei soorten structuur aan opleggen. Die structuur hoeft niet inherent te zijn aan het organisme zelf: hij is eerder een vertaling van de manier waarop wij naar de structuur kijken en hem proberen te begrijpen.
Voorbeeld 1: grammaticaregels zijn een poging om enige ordening te brengen in het ongelooflijk ingewikkelde kluwen van de natuurlijke taal. De grammatica is geen onderdeel van de taal, maar een structuur die er achteraf wordt aan opgelegd om het gedrag van de taalgebruikers te begrijpen.
Voorbeeld 2: een student maakt een schematische voorstelling, op twee bladzijden, van de inhoud van een dikke cursus psychologie.
In de informatica wordt in diverse contexten gebruik gemaakt van Jacksonstructuren om complexiteit te beheersen.
Jackson onderscheidt drie basismechanismen waarmee uit elementaire bouwstenen grotere gehelen worden samengesteld:
Deze drie mechanismen kunnen onderling worden samengesteld, bijvoorbeeld: een sequentie die bestaat uit: eerst een selectie tussen A en B, gevolgd door een iteratie van C.
Voorbeeld: ochtendritueel.
Elke werkdag staat Jan op om 6h30. Hij scheert zich en kleedt zich aan. Daarna stopt hij één voor één de dingen in zijn boekentas die hij de vorige avond heeft klaargelegd. Soms eet hij een boterham. Hij rijdt weg met de auto of met de fiets.
Op het hoogste niveau herkennen we hierin een sequentie:
De eerste drie handelingen zijn elementair, ze kunnen niet verder worden ontleed. De vierde handeling is een iteratie:
4. herhaal 0 of meer keer:
4.1 ding in boekentas steken
De zesde handeling is een selectie.
6. kies precies 1 mogelijkheid uit:
6.1 wegrijden met de auto
6.2 wegrijden met de fiets
De vijfde handeling is eveneens een selectie, met de
bijzondere bijkomstigheid dat 1 van de opties leeg is.
5. kies precies 1 mogelijkheid uit:
5.1 boterham eten
5.2 niets doen
Jacksonstructuren worden vaak voorgesteld aan de hand van een grafische voorstelling die we Jacksondiagram noemen. In een Jacksondiagram neemt elke structuurelement, of het nu een elementaire bouwsteen of een complex geheel is, de vorm aan van een rechthoek. Elementaire bouwstenen worden kort beschreven, indien mogelijk binnen de rechthoek.

Een sequentie van 2 of meer structuurelementen tekenen we als een rechthoek, met daaronder de opeenvolging van de samenstellende delen in de juiste volgorde.
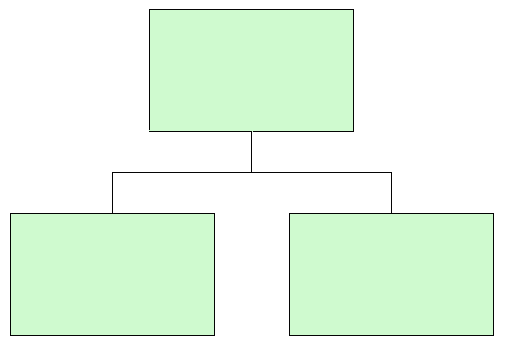
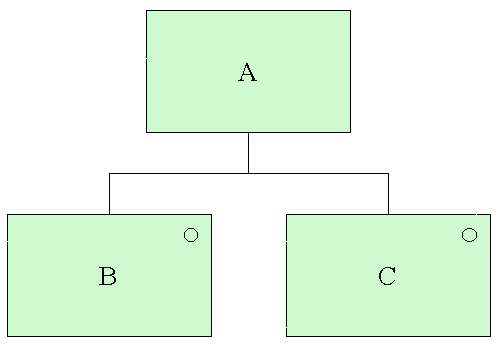
Een selectie van 2 of meer structuurelementen tekenen we als een rechthoek, met daaronder de samenstellende delen in een willekeurige volgorde. Ieder onderdeel wordt bovendien in de rechterbovenhoek van een cirkeltje voorzien.
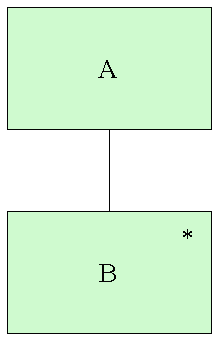
Een iteratie van een structuurelement tekenen we als een rechthoek, met daaronder het te herhalen element. Dat element krijgt in zijn rechterbovenhoek een asterisk.
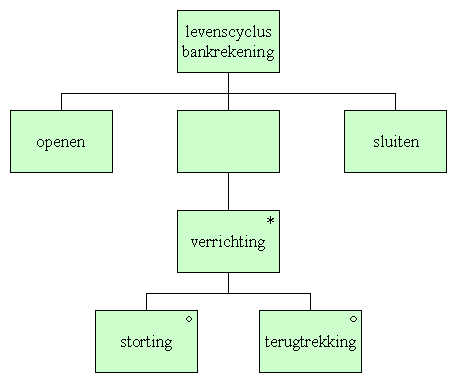
Voorbeeld: de levenscyclus van een bankrekening. De elementaire handelingen die op een bankrekening betrekking hebben, zijn:
Deze handelingen kunnen echter niet in een willekeurige volgorde plaatsvinden: zo kan bijvoorbeeld een rekening die al open is, niet meer geopend worden. De mogelijke volgordes der handelingen wordt bepaald de de volgende Jacksonstructuur:
Het bijbehorende Jacksondiagram ziet er als volgt uit.
Oefening. Teken het Jacksondiagram voor het hoger beschreven ochtendritueel.
Oefening. Een gestandaardiseerd curriculum vitae bij firma X bestaat uit persoonsgegevens, opleiding en werkervaring. De persoonsgegevens zijn: naam en adres, burgerlijke staat, eventuele naam van echtgenoot. De opleiding bestaat uit een aantal diploma's, telkens met vermelding van de onderwijsinstelling en het behaalde resultaat. De werkervaring is een opeenvolging van namen van werkgevers, adressen en begindata van tewerkstelling.
Teken het Jacksondiagram voor de structuur van een dergelijk CV.
De veranderlijken die we tot hiertoe in de
DATA DIVISON definieerden, waren steeds
afzonderlijke, elementaire gegevens (meestal getallen).
De gegevens waarmee bedrijfstoepassingen omgaan, zijn echter
meestal gegroepeerd in grotere gehelen, waarin ieder
gegeven een specifieke rol vervult: we noemen dit
gegevensstructuren.
In een informatiesysteem ten behoeve van de personeelsdienst van een onderneming zou de complexe gegevensstructuur "personeelslid" uit de volgende componenten kunnen bestaan:
Goed programma-ontwerp vereist dat we deze gegevens niet
los van elkaar declareren, maar ze als één geheel
beschouwen, en dit zowel bij de declaratie in de DATA DIVISION
als bij het gebruik in de PROCEDURE DIVISION.
Informatiestructuren kunnen recursief worden opgebouwd. Zo kan in het hogergeciteerde voorbeeld van de datastructuur "personeelslid" het individuele gegevenselement "adres" op zijn beurt als een gegevensstructuur worden opgevat, bestaande uit "straatadres", "postnummer", "gemeente" en "land". En misschien zal een "straatadres" op zijn beurt uiteenvallen in een straat, een huisnummer en een optioneel bus- of appartementnummer.
In gegevensstructuren komen dus ook optionele gedeelten voor: sommige adressen bevatten busnummers, andere niet. Voor sommige personeelsleden (de arbeiders) moeten we het gegeven "uurloon" opslaan, voor anderen het gegeven "maandloon". Dit zijn voorbeelden van het algemene mechanisme dat selectie heet.
Tenslotte kan in de definitie van een gegevensstructuur ook iteratie (herhaling) optreden. Zo kan met een personeelslid bijvoorbeeld een compleet evaluatiedossier worden geassocieerd, waarbij een evaluatiedossier bestaat uit een reeks (van nul of meer) evaluatieverslagen.
We herkennen in het bovenstaande gemakkelijk terug de structuurelementen van Jackson uit paragraaf 5. Inderdaad kunnen Jackson-structuren niet alleen gebruikt worden voor het beschrijven van programmastructuren, maar eveneens voor gegevensstructuren. Het volgende Jackson-diagramma toont een deel van de tot hiertoe geschetste gegevensstructuur "personeelslid":
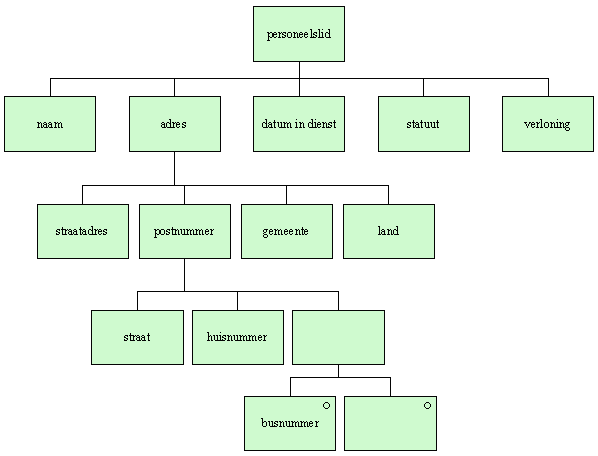
In een Cobolprogramma definieert de Data Division de gebruikte gegevenstypes. Gestructureerde gegevenstypes worden weergegeven aan de hand van level indicators (niveaunummers).
Ieder gegevenselement in de Data Division wordt voorafgegaan door
zijn niveaunummer, dat is een getal van twee cijfers. Elementen
van het hoogste niveau worden (misschien niet zo onlogisch als
het lijkt) weergegeven door de laagste nummers. Bovenstaand
Jacksondiagramma zou bijvoorbeeld aanleiding kunnen geven
tot de volgende structuur in de WORKING-STORAGE SECTION:
01 PERSONEELSLID.
05 NAAM PIC X(50).
05 ADRES.
10 STRAATADRES.
50 STRAAT PIC X(30).
50 NUMMER PIC ZZZ9.
50 EXTRA_NR PIC ZZZ9.
10 POSTNUMMER PIC 9999.
10 GEMEENTE PIC X(30).
10 LAND PIC X(30).
05 STATUUT PIC X.
05 VERLONING PIC Z(6)9V99.
De indentatie is niet verplicht maar bevordert de leesbaarheid (en dus de onderhoudbaarheid) van het programma. De nummers 66, 77 en 88 hebben speciale betekenissen en mogen niet voor gewone structuurelementen gebruikt worden. Het is waarschijnlijk sowieso een goed idee, geen nummers boven de 50 te gebruiken. De speciale betekenis van het nummer 77 kennen we trouwens al: het zijn alleenstaande, niet-gestructureerde gegevenselementen.
Een iteratieve gegevensstructuur wordt vaak met de Engelse
term repeating group aangeduid. In een Cobol-programma
geven we dit aan door de OCCURS-clausule. Na de declaratie
van het desbetreffende gegevenselement geven we met het sleutelwoord
OCCURS aan, hoe vaak deze structuur voorkomt:
01 PERSONEELSLID.
02 NAAM PIC X(50).
02 EVALUATIEDOSSIER.
03 EVALUATIE OCCURS 5 TIMES.
04 DATUM PIC 999999.
04 OORDEEL PIC X(50).
02 AFDELING PIC X(20).
01 EVAL.
04 DATE PIC 999999.
04 GRADE PIC X(50).
In de PROCEDURE DIVISION kunnen we naar de individuele
evaluaties verwijzen door een nummering tussen haakjes. Zo zullen
de volgende Cobol-opdrachten de vierde evaluatie uit de reeks
overbrengen naar de afzonderlijke veranderlijke EVAL,
om dan de datum en de toegekende graad afzonderlijk af te drukken:
MOVE EVALUATIE(4) TO EVAL. DISPLAY DATE. DISPLAY GRADE.
Het volgende programma drukt een tabel af van machtsverheffingen van natuurlijke getallen, gaande van 11 = 1 tot en met 56 = 5625. Het bevat een dubbele iteratieve gegevensstructuur: de resultatentabel is een verzameling rijen, en iedere rij bestaat uit een aantal afzonderlijke resultaten. Individuele resultaten worden geadresseerd door tussen de haakjes twee afzonderlijke indices te vermelden, gescheiden door een komma:
Move INHOUD To ELEMENT(TELLER1, TELLER2).
Het programma vult eerst de hele tabel in het geheugen, en begint pas daarna de resultaten af te drukken. Uiteraard hadden we ook (en efficiënter) telkens een afzonderlijke resultatenrij kunnen berekenen en afdrukken. Het huidige programma laat ons echter toe, de dubbele iteratie te illustreren.
Identification Division.
Program-id. DubbelRij.
Author. Lieven Smits.
Environment Division.
Data Division.
Working-Storage Section.
77 TELLER1 PIC 99.
77 TELLER2 PIC 99.
77 INHOUD PIC 9999.
01 TABEL.
02 RIJ OCCURS 5 TIMES.
03 ELEMENT PIC ZZZZ9 OCCURS 6 TIMES.
Procedure Division.
Hoofdprogramma.
Perform Vul-tabel.
Perform Toon-tabel.
Stop Run.
Vul-tabel.
Perform Vul-rij Varying TELLER1
From 1 By 1 Until TELLER1 > 5.
Vul-rij.
Move Zeroes To RIJ(TELLER1).
Perform Vul-element Varying TELLER2
From 1 By 1 Until TELLER2 > 6.
Vul-element.
Compute INHOUD = TELLER1 ** TELLER2.
Move INHOUD To ELEMENT(TELLER1, TELLER2).
Toon-tabel.
Perform Toon-rij Varying TELLER1
From 1 By 1 Until TELLER1 > 5.
Toon-rij.
Display RIJ(TELLER1).
Een iteratieve gegevensstructuur wordt in de informatica meestal aangeduid met de Engelse term array. In het Nederlands spreken we soms van een rij-veranderlijke of kortweg rij.
In een goed gestructureerd programma bestaat er een duidelijke
overeenkomst tussen enerzijds de gegevensstructuren waarin informatie
wordt opgeslagen, en anderzijds de programmastructuren die met die
informatie werken. In het bovenstaande programma zien we dat met
ieder iteratieniveau in de dubbele array TABEL
een afzonderlijke procedurele paragraaf overeenkomt:
Vul-tabel handelt op het niveau van de
complete gegevensstructuur 01 TABELVul-rij behandelt één
afzonderlijk tabelelement van het deeltype 02 RIJVul-element aan
een individueel (atomair) gegeven van het type 03 ELEMENTPersistente gegevens zijn gegevens waarvan de levensduur langer is dan de uitvoering van één computerprogramma. Technisch wordt persistentie meestal gerealiseerd door gegevens te bewaren in bestanden op een magnetisch of optisch opslagmedium zoals een magneetband, een floppy disk, een harde schijf of een CD.
Programma's of programma-onderdelen die gebruik maken van bestanden om persistente informatie te manipuleren, vallen ruwweg uiteen in twee categorieën:
De eerste categorie leest de gegevens van een bestand éénmaal, in de volgorde waarin ze in het bestand voorkomen. Na eventuele bewerkingen of wijzigingen worden de gegevens éénmaal weggeschreven in de volgorde waarin ze in het bestand voorkomen.
Bij dit gebruik van bestanden is er een duidelijk onderscheid tussen de lees- en de schrijffase: eenzelfde bestand wordt niet tegelijkertijd voor lezen en schrijven gebruikt.
De tweede categorie van programma's staat min of meer permanent in verbinding met een bestand. Van dit bestand worden af en toe gedeelten gelezen en/of overschreven.
Lees- en schrijfoperaties kunnen door elkaar voorkomen, en in een volgorde die geen verband houdt met de volgorde van de gegevens in het bestand.
De meeste tekstverwerkers (zoals MS Word) en rekenbladprogramma's (zoals MS Excel) vallen in de eerste categorie. De gebruiker opent eerst een bestand, dat door het programma in zijn geheel gelezen wordt van voor naar achter. Na een reeks bewerkingen besluit de gebruiker de informatie (tekst, spreadsheet) opnieuw te bewaren. Op dat moment wordt alle informatie in volgorde naar het bestand weggeschreven.
Er is geen interactie met de harde schijf tenzij de gebruiker daar uitdrukkelijk om vraagt met de bevelen Open en Save.
De meeste gegevensbankprogramma's (zoals MS Access) vallen in de tweede categorie. Het programma staat voortdurend in verbinding met het bestand. Je kan bijvoorbeeld met MS Access geen nieuwe database creëren in het geheugen van de computer zonder eerst uitdrukkelijk aan te geven waar, en onder welke naam, die database zich op de harde schijf zal gaan bevinden.
Lees- en schrijfoperaties gebeuren daarna automatisch en in een willekeurige volgorde. Zo is er bijvoorbeeld in MS Access géén uitdrukkelijk bevel om gewijzigde gegevens te bewaren (het Save-commando dient slechts om wijzigingen aan queries, tabelstructuren e.d. te bewaren). Gegevens bewaart Access automatisch, ondermeer telkens wanneer je naar een volgende tabelrij navigeert.
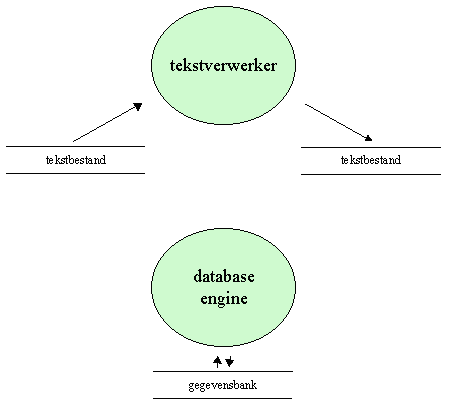
In het eerste geval spreken we van sequentiële bestandstoegang (Engels: sequential access). De tweede categorie bepaalt willekeurige bestandstoegang (Engels: random access).
De manier waarop de informatie van een bestand technisch georganiseerd is op het dragende medium, noemen we de organisatie van het bestand. Ze is gekoppeld aan het bestand zelf, niet aan de programma's die ermee omgaan. Natuurlijk zal een programma dat een bestand gebruikt, rekening moeten houden met de organisatie van dat bestand.
SEQUENTIAL
De eenvoudigste organisatievorm is de sequentiële organisatie. Hierbij worden de records in een welbepaalde volgorde achter elkaar bewaard. Om een bepaald record te kunnen adresseren, moeten eerst alle voorafgaande records worden overlopen. Er is geen manier om voorafgaand rechtstreeks de positie van een record op het opslagmedium te berekenen.

Een bestand met sequentiële organisatie zal uitsluitend via sequentiële toegang door programma's kunnen worden aangesproken. Het omgekeerde is echter niet waar: ook andere organisatievormen kunnen via sequentiële toegang gelezen of geschreven worden.
RELATIVE
Een bestand is relatief georganiseerd als de records op natuurlijke wijze genummerd zijn vanaf 1, 2, 3,... en bovendien een vaste lengte hebben. In dat geval kan de positie van een record op het opslagmedium direct berekend worden aan de hand van zijn nummer: record nummer n begint op karakterpositie n × recordlengte.
Bestanden met relatieve organisatie worden in Cobol steeds gebruikt via willekeurige toegang. Het omgekeerde is echter niet waar: ook andere organisatievormen kunnen via willekeurige toegang gelezen en geschreven worden.
INDEXED
De geïndexeerde organisatievorm combineert de ordening van een sequentieel bestand met de directe toegankelijkheid van een relatief bestand. Een geïndexeerd bestand is opgebouwd uit twee delen: enerzijds de netto inhoud, die bestaat uit een reeks records waarvan de rangschikking vergelijkbaar is met de relatieve organisatie. De nummering van de recors is echter intern, ze is niet toegankelijk voor gebruikers of programma's. Anderzijds bevat het bestand ook één of meer indices. Een index is een informatiestructuur die een kenmerk van een record op efficiënte wijze associeert met het interne volgnummer van dat record.
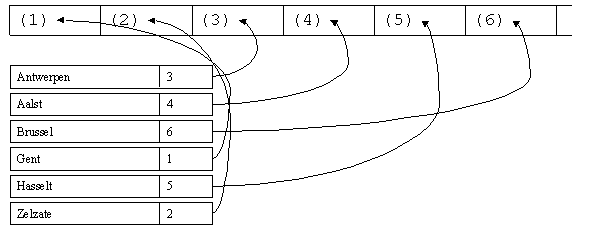
Geïndexeerde bestanden kunnen zowel sequentieel als willekeurig worden gebruikt. Er bestaat zelfs een speciale toegangsvorm, zogenaamde dynamische toegang, die een programma op de twee verschillende manieren toegang biedt tot eenzelfde geïndexeerd bestand.
De programmeertaal Cobol is speciaal ontworpen voor de aanmaak, het onderhoud en het gebruik van bestanden. We vinden dan ook elementen van bestandsgebruik terug in maar liefst drie van de vier programmadivisies:
ENVIRONMENT DIVISION leggen we
vast hoe de bestanden heten in de externe omgeving van het
programma en koppelen we daaraan telkens een interne
benaming om naar het bestand te kunnen verwijzen.
We bepalen tevens de organisatievorm en de toegangsmodaliteit
van elk bestand.
DATA DIVISION definiëren we
de elementaire gegevensstructuren die aan de bestanden
ten grondslag liggen.PROCEDURE DIVISION hebben we de beschikking
over opdrachten om een bestand te openen en te sluiten,
en om één gegevensstructuur uit het bestand
te lezen of ernaar weg te schrijven.
Om met bestanden te werken, gebruiken we de INPUT-OUTPUT SECTION
van de ENVIRONMENT DIVISION. Na de openingszin
FILE-CONTROL.
definiëren we elk bestand afzonderlijk met een SELECT-clausule:
SELECT <interne bestandsnaam> ASSIGN TO (INPUT|OUTPUT) <externe bestandsnaam>
Hierbij is <interne bestandsnaam>
een geldige Cobol-naam
die verder in het programma zal gebruikt worden om dit bestand te identificeren.
Met (INPUT|OUTPUT) bedoelen we het woord INPUT
of het woord OUTPUT, indien het bestand slechts in één
van deze twee richtingen gebruikt zal worden. De
<externe bestandsnaam> is de naam van het
bestand zoals die door het beheerssysteem (operating system)
gehanteerd wordt, tussen een paar dubbele aanhalingstekens.
Daarbij kan gebruik gemaakt worden van volledige
padnamen, inclusief schijfletters en mappen, volgens de conventies
die het operating system dienaangaande hanteert.
In RMCobol geldt een relatieve padnaam, of een afzonderlijke bestandsnaam zonder pad, ten opzichte van de session directory (niet te verwarren met de project directory).
De SELECT-clausule wordt onmiddellijk gevolgd door een
bepaling van de organisatie en de toegang van het
bestand. Met de toegang bedoelen we: of we het bestand sequentieel
(SEQUENTIAL)
dan wel willekeurig (RANDOM) willen gebruiken. De toegangsmodus
DYNAMIC slaat op de combinatie van beiden.
De organisatie is SEQUENTIAL, RELATIVE
of SEQUENTIAL.
ORGANIZATION IS <organisatievorm> ACCESS IS <toegangsmodaliteit>
Zoals eerder uiteengezet, is niet elke combinatie organisatie/toegang mogelijk. Onderstaande tabel geeft de mogelijke combinaties weer met een kruisje.
| ACCESS IS | ORGANIZATION IS | ||
|---|---|---|---|
| SEQUENTIAL | RELATIVE | INDEXED | |
| SEQUENTIAL | × | × | |
| RANDOM | × | × | |
| DYNAMIC | × | ||
Bij een RELATIVE bestand hoort een specificatie van
de geheugenstructuur die het nummer van het huidige record bevat.
Deze geheugenstructuur mag geen deel uitmaken van
de eigen recordstructuur van het bestand. Hij is dus ofwel een deel
van een recordstructuur van een ander bestand, ofwel een
variabele in het werkgeheugen, te declareren in de
WORKING-STORAGE SECTION van de DATA DIVISION.
De vorm van deze specificatie luidt
RELATIVE KEY IS <structuurnaam>
Bij een INDEXED bestand hoort een specificatie van
de geheugenstructuur die, als onderdeel van een record, die record
identificeert en onderscheidt van de andere records. We spreken
van de sleutel van de recordstructuur.
RECORD KEY IS <deelstructuur>
Het volgende programmadeel declareert twee sequentiële bestanden die zich
in de session directory zullen bevinden. Het
eerste is een invoerbestand met de naam "Lijst.txt", waarnaar we intern zullen
verwijzen met de naam PERSOON-IN. Het tweede is een uitvoerbestand
met de naam "Lijst2.txt" dat we intern PERSOON-UIT noemen.
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT PERSOON-IN ASSIGN TO INPUT "Lijst.txt"
ORGANIZATION IS SEQUENTIAL
ACCESS IS SEQUENTIAL.
SELECT PERSOON-UIT ASSIGN TO OUTPUT "Lijst2.txt"
ORGANIZATION IS SEQUENTIAL
ACCESS IS SEQUENTIAL.
Het volgende programmadeel declareert een sequentieel invoerbestand,
een relatief uitvoerbestand en een geïndexeerd uitvoerbestand.
Merk op dat bij de uitvoerbestanden
het woord OUTPUT niet vermeld wordt: de toegangsmode
RANDOM laat namelijk zowel invoer als uitvoer toe.
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT PUNTEN-IN ASSIGN TO INPUT "punten.txt"
ORGANIZATION IS SEQUENTIAL
ACCESS MODE IS SEQUENTIAL.
SELECT PUNTEN-UIT-1 ASSIGN TO "punten.raf"
ORGANIZATION IS RELATIVE
ACCESS MODE IS RANDOM
RELATIVE KEY IS PUNT-NR.
SELECT PUNTEN-UIT-2 ASSIGN TO "punten.idx"
ORGANIZATION IS INDEXED
ACCESS MODE IS RANDOM
RECORD KEY IS UIT-2-STUDENTNUMMER.
De invulling van een Cobol-bestand bestaat uit een opeenvolging van records: gegevensgroepen met een welgedefinieerde gemeenschappelijke structuur. Lees- een schrijfbewerkingen vanuit een Cobol-programma gebeuren altijd met hele records of verzamelingen records, nooit met kleinere eenheden.
In de DATA DIVISION dient de FILE SECTION voor de
beschrijving van de record-structuren van de verschillende bestanden. Met ieder
bestand wordt een file description-element geassocieerd, herkenbaar
aan de lettercode FD in de achtste kolom, gevolgd door de
interne naam van het bestand zoals eerder bepaald in de ENVIRONMENT
DIVISION.
Daarna komen drie verplichte bepalingen vanaf kolom 12:
RECORD CONTAINS <getal> CHARACTERS
LABEL RECORD IS OMITTED
FILE SECTION nader bepaald worden
DATA RECORD IS <structuurnaam>.
Daaronder komen de definities van de gegevensstructuren, met dezelfde
hiërarchische conventies als in de WORKING-STORAGE SECTION,
d.w.z. aan de hand van niveaunummers (het nummer 77, voor losstaande
gegevens, komt hier echter niet meer voor).
Voor wat betreft het bestand PERSOON-IN van voorbeeld 1
in paragraaf 7.2.1 zou de beschrijving in de FILE SECTION
van de DATA DIVISION er als volgt kunnen uitzien.
FD PERSOON-IN
RECORD CONTAINS 97 CHARACTERS
LABEL RECORD IS OMITTED
DATA RECORD IS INREC.
01 INREC.
02 NAAM.
03 FAMILIENAAM PIC X(20).
03 VOORNAAM PIC X(20).
02 STRAAT PIC X(25).
02 POSTNUMMER PIC X(10).
02 GEMEENTE PIC X(20).
02 REGELEINDE PIC X(2).
Als de records overeenkomen met de individuele regels in een gewoon
tekstbestand, dan moet op het einde van de record plaats worden
voorzien voor het teken of de tekens die de computer gebruikt
om regels van elkaar te scheiden. In MS-DOS zijn dit bijvoorbeeld
2 tekens, vandaar het gegevenselement REGELEINDE in
bovenstaande declaratie.
De DATA DIVISION die volgt op voorbeeld 2 van
paragraaf 7.2.1, zou minimaal de volgende elementen moeten
bevatten.
DATA DIVISION.
FILE SECTION.
FD PUNTEN-IN
RECORD CONTAINS 80 CHARACTERS
LABEL RECORD IS OMITTED
DATA RECORD IS INREC.
01 INREC.
02 NETTO.
03 IN-STUDENTNUMMER PIC 9(6).
03 IN-STUDENTNAAM PIC X(30).
03 IN-MODULECODE PIC X(6).
03 IN-MODULENAAM PIC X(30).
03 IN-KWOTERING PIC 99.
02 REGELEINDE PIC XX.
FD PUNTEN-UIT-1
RECORD CONTAINS 78 CHARACTERS
LABEL RECORD IS OMITTED
DATA RECORD IS OUTREC-1.
01 OUTREC-1.
02 UIT-1-STUDENTNUMMER PIC 9(6).
02 UIT-1-STUDENTNAAM PIC X(30).
02 UIT-1-MODULECODE PIC X(6).
02 UIT-1-MODULENAAM PIC X(30).
02 UIT-1-KWOTERING PIC 99.
FD PUNTEN-UIT-2
RECORD CONTAINS 78 CHARACTERS
LABEL RECORD IS OMITTED
DATA RECORD IS OUTREC-2.
01 OUTREC-2.
02 UIT-2-STUDENTNUMMER PIC 9(6).
02 UIT-2-STUDENTNAAM PIC X(30).
02 UIT-2-MODULECODE PIC X(6).
02 UIT-2-MODULENAAM PIC X(30).
02 UIT-2-KWOTERING PIC 99.
WORKING-STORAGE SECTION.
77 PUNT-NR PIC 9999.
In de (deel)programma's van de PROCEDURE DIVISION
staan nu enkele opdrachten te onzer beschikking om met
de bestanden te interageren. In elk geval moet de interactie
met een bestand beginnen met een OPEN-opdracht.
Deze heeft verschillende vormen naargelang het een
invoer- of een uitvoerbestand betreft:
OPEN INPUT <interne bestandsnaam> .
OPEN OUTPUT <internet bestandsnaam> .
Elk van beide opdrachten mag worden voorzien van de optionele
clausule WITH NO REWIND. Dit is slechts zinvol
in het geval van sequentiële toegang: dan begint het
lezen of schrijven op de plaats waar het eventueel tevoren
was opgehouden in plaats van bij het begin van het bestand.
Bij willekeurige toegang bestaat ook de mogelijkheid
OPEN I-O <interne bestandsnaam> .
Na de laatste lees- of schrijfoperatie moet het bestand worden afgesloten met de opdracht
CLOSE <interne bestandsnaam> .
Een individuele leesopdracht neemt de vorm
READ <interne bestandsnaam> RECORD .
Deze opdracht heeft tot gevolg dat een record
van het genoemde bestand gelezen wordt (bij sequentiële
toegang het eerstvolgende, bij willekeurige toegang zoals
aangegeven door de sleutel), en dat de inhoud
ervan in het overeenkomstige gegevensrecord uit de DATA
DIVISION wordt geplaatst.
Bij sequentiële toegang bestaat ook een uitgebreide vorm van de leesopdracht die nagaat of de laatste record gelezen is, en die in dat geval passende maatregelen neemt (bijvoorbeeld, aangeven dat een lusopdracht kan beëindigd worden).
READ <interne bestandsnaam> RECORD
AT END <opdracht> .
Het volgende deelprogramma "Lees-adressen" leest alle
familienamen uit het hierboven gedefinieerde bestand
en toont ze op het scherm. We veronderstellen dat er
een veranderlijke EINDE is gedeclareerd
die één letterteken kan bevatten.
Lees-adressen.
MOVE 'N' TO EINDE.
OPEN INPUT PERSOON-IN.
PERFORM Enkel-adres UNTIL EINDE IS EQUAL TO 'Y'.
CLOSE PERSOON-IN.
STOP RUN.
Enkel-adres.
READ PERSOON-IN RECORD
AT END MOVE 'Y' TO EINDE.
IF EINDE IS EQUAL TO 'N'
DISPLAY FAMILIENAAM.
Bij willekeurige toegang kan dan weer geverifieerd worden of de toegepaste sleutelwaarde (nummer voor relatief bestand, recordsleutel voor geïndexeerd bestand) geldig is:
READ <interne bestandsnaam> RECORD
INVALID KEY <opdracht> .
De opdracht
WRITE <record-structuurnaam> .
schrijft de inhoud van het gegevensrecord van de DATA
DIVISION op de juiste plaats in het bestand:
achteraan bij sequentiële toegang, of zoals aangegeven
door de sleutel bij willekeurige toegang.
Vervolledig bovenstaand voorbeeld 1 tot een compleet werkend programma. Maak een invoerbestand om het te testen. Als je over de elektronische versie van deze tekst beschikt, kan je een invoerbestand downloaden.
http://www.ster.be/cobol/
![]()